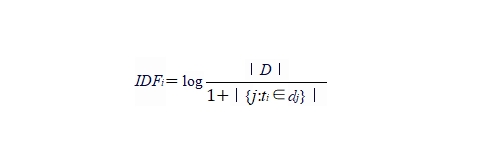
了解搜索引擎是如何提取关键词,是每个SEO必须必须知道的,否则很容易一不小心优化了个寂寞。如果你认为关键词就是自己在页面keywords中设置的关键词,或者只要重复某个词就可以成为关键词,那你一定要听劝看完这篇文章。
关键词的重要性
对于用户来说在搜索引擎获取内容的方式是,输入关键词获取检索结果然后选择查看自己感兴趣的内容。
对于搜索引擎,则需要将用户的搜索关键词,匹配到关键性最高的内容,精准高效解决用户的搜索需求是搜索引擎生存的根本。
搜索引擎是如何快速显示结果
搜索引擎中存有海量的内容,因此搜索引擎绝不可能是根据用户的搜索关键词去海量的内容中进行匹配,效率和成本因素都不允许这么去做。
搜索引擎的索引结构主要实现的是“关键词-文档”的映射关系,即将用户输入的关键词与包含这些关键词的文档关联起来。这种映射关系通过特定的数据结构来实现,其中最常见且最高效的是倒排索引。
搜索引擎是如何提取关键词的
接下来来到今天的重点,搜索引擎是如何提取关键词的。对于我们人类是直接理解整片文章的含义,但是对于搜索引擎是对整篇文章进行划分成需求关键词和短语,通过算法计算文章和各个关键词的关键程度。
文本预处理
首先,搜索引擎通过爬虫(Spider)程序在互联网上抓取网页内容,对抓取的网页进行预处理,搜索引擎会去除网页内容中的HTML标签,只保留纯文本内容。
去除停用词: 停用词是指那些在语言中非常常见但对文档内容理解没有实质性帮助的词汇,如“的”、“是”、“在”等。搜索引擎会将这些词汇从文本中去除,以减少索引大小并提高搜索效率。
分词: 对于中文等不进行自然空格分隔的语言,搜索引擎会使用分词技术将文本分割成有意义的词汇单元(即词或短语)。这通常通过基于规则的分词、基于统计的分词或混合方法来实现。
关键词提取
搜索引擎提取关键词的过程是一个复杂而精细的自然语言处理(NLP)任务,它涉及多个步骤和技术。涉及的算法较多简单的列举一些代表性的,关注潘某人SEO后期对于重点的做详细解说。
基于统计学的方法
TF-IDF(Term Frequency-Inverse Document Frequency):是最常用的关键词提取方法之一。它考虑了一个词在文档中出现的频率(TF)以及该词在整个文档集合中的普遍重要性(IDF)。TF-IDF值越高的词,越有可能是关键词。
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF值用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。词语的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。这种计算方法可以帮助我们过滤掉一些常见的词语(如“的”、“是”等),因为它们对于大多数文件都是重要的,但对于区分文件内容并不具有特别的意义。

TF-IDF值越高,表示该词语对于文件的重要性越高,越能够代表该文件的主题。这种方法在搜索引擎的文本挖掘中被广泛使用,用以评估用户查询与文件之间的相关性。
TextRank:是一种基于图的排序算法,通过构建文本中单词的共现图来计算单词的重要性,从而提取关键词。
TextRank算法通过把文本分割成若干组成单元(如句子或词语),并构建节点连接图,利用节点之间的关系来评估节点的重要性。这些关系可以是共现关系、语义相似度等,并通过迭代计算得到每个节点的权重值,最终根据权重值对节点进行排名。
TextRank算法可以用于从文本中提取关键词。它通过将文本中的词语视为图的节点,词语之间的关系(如共现关系)视为图的边,并通过迭代计算得到每个词语的权重值,最终根据权重值的高低提取出重要的关键词。
TextRank算法是一种无监督学习方法,它不需要额外的训练数据,仅依赖于文本本身的信息进行关键词提取和文本摘要。
基于机器学习的方法:
使用机器学习算法(如支持向量机SVM、朴素贝叶斯Naive Bayes等)从大量训练数据中学习如何确定关键词。这些算法能够自动学习并识别出与特定主题相关的关键词。
向量机SVM,全称为Support Vector Machine(支持向量机),是一种在机器学习领域广泛应用的算法,主要用于模式识别、分类以及回归分析。搜索引擎需要对海量的网页进行分类和索引,以便快速响应用户的查询请求。SVM算法因其良好的分类性能和泛化能力,常被用于网页内容的分类。通过训练SVM模型,可以自动将网页划分为不同的类别,如新闻、科技、娱乐等,从而帮助用户更快地找到所需信息。
搜索引擎中,朴素贝叶斯(Naive Bayes, NB)算法作为一种经典的机器学习算法,具有广泛的应用。搜索引擎需要对海量的网页进行分类和索引,以便快速响应用户的查询请求。朴素贝叶斯算法因其简单高效的特点,常被用于网页内容的分类。例如,将网页分为新闻、科技、娱乐等不同类别,以便用户能够更准确地找到所需信息。在搜索引擎中,用户的查询意图往往多种多样。朴素贝叶斯算法可以通过分析用户的查询历史、点击行为等特征,识别用户的查询意图,并推荐相关的搜索结果。这有助于提升搜索引擎的用户体验,使用户能够更快地找到所需信息。
基于词性标注的方法:
通过分析文本中单词的词性(如名词、动词等)来确定关键词。通常,名词和动词更有可能成为关键词。常用的词性标注工具有Stanford CoreNLP、NLTK等。
人工干预:
对于一些特定的领域或主题,搜索引擎可能会通过人工干预的方式来选择关键词。例如,在新闻搜索中,编辑可能会手动为新闻报道添加关键词标签。
搜索引擎提取关键词是一个复杂而精细的过程,涉及多个步骤和方法。通过这些方法和技术手段的结合应用,搜索引擎能够准确地提取出与网页内容相关的关键词,并为用户提供高质量的搜索结果。
关键词优化与筛选
提取出的关键词可能数量较多,搜索引擎还需要对这些关键词进行优化和筛选:去除重复的关键词,并对意思相近的关键词进行合并;根据关键词在文档中的位置(如标题、段落开头等)、词频、TF-IDF值等因素评估关键词的重要性;结合用户查询意图和上下文信息,选择最符合用户需求的关键词。
因此,对于站点使用以前的堆砌关键词的方法获取排名已经是行不通的,各个算法多维度的取长补短,尤其是NLP从早期的规则和语法分析,到基于统计的方法,再到近年来深度学习的广泛应用,NLP技术不断取得突破性进展。
深度学习的兴起极大地推动了NLP的发展,卷积神经网络(CNN)和循环神经网络(RNN)等技术被广泛应用。近年来,基于(Transformer)的模型(如BERT、GPT等)在多个NLP任务上取得了突破性进展,显著提高了语言理解和生成的能力。
如何做好关键词优化
对于一篇文章来说,我们可以理解成多个关键词的合集,但是我们要做的就是突出需要优化关键词与文章的关联性。而这个关键性不能简单的只是基于词频上,内容语意上也要有足够的关联性。
对于seo中常见的TDK标签,潘某人SEO认为其中的title标签较为重要之外,在语意化之下其余两者的重要度有限,即使忽略留空也未尝不可。重点优化title标签即可,title标签直接作用于用户的点击意向。
一个合格的标题应该承载包含所需优化的关键词,并且标题也要成为整个页面的大意中心。