在SEO优化中有很多情况需要对蜘蛛进行屏蔽,那么作为一个SEO就必须知道屏蔽搜索引擎蜘蛛的常见方案,以及结合实践采用正确的方法来屏蔽蜘蛛。合理的对蜘蛛进行屏蔽可以避免重复内容、不适宜展示的等内容的抓取,可以提供搜索引擎蜘蛛的抓取效率。
常见的蜘蛛屏蔽方法
robots.txt文件: 在网站的根目录下创建或编辑robots.txt文件,明确告诉搜索引擎爬虫哪些目录或页面是不允许访问的。
robots.txt文件是网站与搜索引擎爬虫之间的一种通信协议,它告诉搜索引擎爬虫哪些目录或页面是可以访问的,哪些是不可以访问的;也可以对不同的蜘蛛进行不抓取范围的限制。这个文件通常位于网站的根目录下,并且可以通过在浏览器的地址栏中输入“网站域名/robots.txt”来访问。
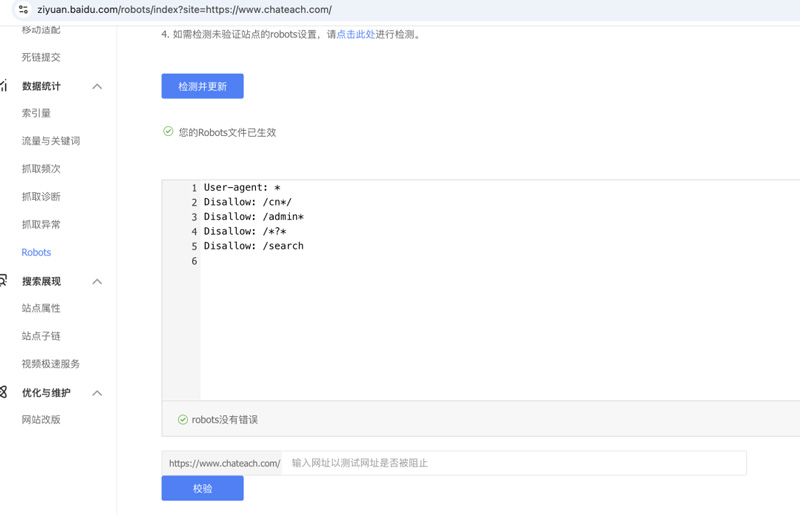
对于百度搜索引擎,在配置robots文件之后,在百度资源后台如上图所示,点击检测更新,可以加快生效,并且可以测试访问来验证配置是否编写正确。
若站点不配置robots.txt文件,意味着网站没有任何的抓取限制,任何的蜘蛛可以对站点的任何可以访问的资源进行抓取。但是建议所有站点进行此配置,不仅仅是基于SEO优化,也是对于站点数据的保护,是对于爬虫使用者进行法律责任追溯的依据。如果发现爬虫行为侵犯了网站的合法权益,网站管理员可以通过法律途径进行维权。
使用meta标签屏蔽
<meta name="robots" content="noindex, nofollow">
<meta name="robots" content="index, nofollow">
<meta name="robots" content="noindex, follow">
<meta name="robots" content="index, follow">
2
3
4
meta标签通常用于定义页面的元数据,但也可以在某些情况下用于告诉搜索引擎不要索引和跟随特定页面,可以有上面4种组合结果。
noindex: 指示搜索引擎不要将当前页面的内容添加到其索引中。这意味着,即使搜索引擎爬虫访问了这个页面,该页面的内容也不会在搜索结果中显示。然而,这并不影响搜索引擎抓取和解析页面上的其他内容(如链接)。
index: 这个指令告诉搜索引擎可以将当前页面的内容添加到其索引中。这意味着,如果搜索引擎爬虫访问了这个页面,并且该页面符合搜索引擎的抓取和索引标准,那么该页面的内容可能会在搜索结果中显示。
nofollow: 这个指令指示搜索引擎爬虫不要跟踪当前页面上的任何出站链接。也就是说,即使爬虫访问了这个页面,它也不会进一步访问这些链接指向的其他页面,也不会将这些页面添加到其索引中(除非这些页面通过其他方式被发现和索引)。
follow: 指示搜索引擎爬虫应该继续跟踪当前页面上的所有链接,并访问这些链接指向的其他页面。即使当前页面本身不被索引,其上的链接仍然可以被爬虫发现,并可能导致这些链接指向的页面被索引。
name=“robots” 指定了这个元标签是为搜索引擎爬虫(robots)提供的指令。如果要针对某个搜索引擎蜘蛛进行屏蔽,修改为对应搜索引擎蜘蛛的名称即可。
使用服务器配置
如果发现提交了robots之后还是存在抓取的情况,可以使用以下的方法进行屏蔽。站点可以通过服务器配置,来进行访问屏蔽。
对于使用Nginx服务器的网站,可以在Nginx的配置文件中添加特定的指令来禁止特定的爬虫访问,不防小人,伪造客户端ua可绕过。例如,以下配置将禁止名为spider(包含关系)的爬虫访问网站的panmourenseo目录:
location /panmourenseo/ {
if ($http_user_agent ~* "spider") {
return 403; # 对蜘蛛返回 403 Forbidden
}
}
2
3
4
5
后端屏蔽抓取
在网站的后端脚本中,可以通过检查HTTP请求中的User-Agent字段来识别并禁止特定的爬虫访问。原理与上述通过服务器屏蔽的原理一致,都是基于客户端的ua来实现。但是后端屏蔽可以具有更高的灵活性。
采用何种方式屏蔽蜘蛛
对于大多数的站点只需要使用第一种robots.txt文件的方法就可以了,但是如果发现一些不该收录的内容存在收录的情况,和结合其它几种方法共同使用。
划重点对于一些已经收录的内容,在使用robots.txt文件的方案进行屏蔽,你会发现过了一段时间之后收录依旧没有被删除,这是因为生效周期比较长。在一些特殊情况下就可以采用服务器配置来屏蔽蜘蛛的访问,然后对这些内容提交死链,可以更快速的进行收录的删除。