有时候会遇到这种情况,在搜索引擎上找到了需要的内容,但是点击进去网站之后,发现和搜索引擎中的检索结果无关,甚至有的页面连主题都不相关。为什么会有这种情况出现呢?
常见的因素
导致这种结果的原因可能有多重情况,下面潘某人SEO举出常见的几种情况。
description标签
搜索引擎除了抓取页面的内容作为搜索结果页的展示,还会将description标签的内容也作为展示内容,而description的内容是无法在页面直接显示的。这种情况非常好确认,直接查看网页源代码的description标签即可,如今出现这种情况出现的概率并不高。
页面更新
这种情况就比较常见,很多时候是站点更新了网页内容,但是搜索引擎还未抓取到更新,所以在搜索引擎检索的结果中还是显示了之前页面的收录的快照内容。
这种情况一般虽然内容不一致,但是主题和内容的相关性还是保持一致;但是如果不仅是内容不一致,主题和内容的差异都比较大,那就是有更深层次的原因。
非常规因素
除了上面这几种常见的情况之外,还有可能是站点存在被挂马劫持或者是站点特意为之。
网站挂马被黑
当网站被挂马后,搜索引擎可能仍然显示旧的、未被篡改的内容,而实际访问时则显示被篡改后的内容,从而导致搜索与显示结果不一致。或者会根据访问类型来进行跳转劫持。
对于访问类型是正常用户非搜索引擎的访问,会进行跳转到目标页面或者是篡改页面内容;因此就导致搜索引擎抓取的一直是网站的内容,而访问访问到的是篡改后的内容。
站点SEO策略
一些站点在实际运营中,因为各种原因导致最终要将页面进行特殊处理,如果适配各个搜索引擎的差异化功能或者是资源权限问题等因素。这类站点会会将同一个页面分为用户页面和爬虫页面,如果一些网站资源需要登录或者是会员制的,但是又要做SEO优化。为了更好SEO优化,会专门在做一套爬虫页,与用户访问页面不同,无需任何的登录等操作,就可以抓取到一些资源。
实现方式
对于这种差异化的显示基本都是通过检测访问者的HTTP请求头之User-Agent可以知道是什么浏览器、什么设备类型,来判断是搜索引擎还是正常用户。只要排除掉需要优化的搜索引擎的UA中的蜘蛛名称,即可实现。
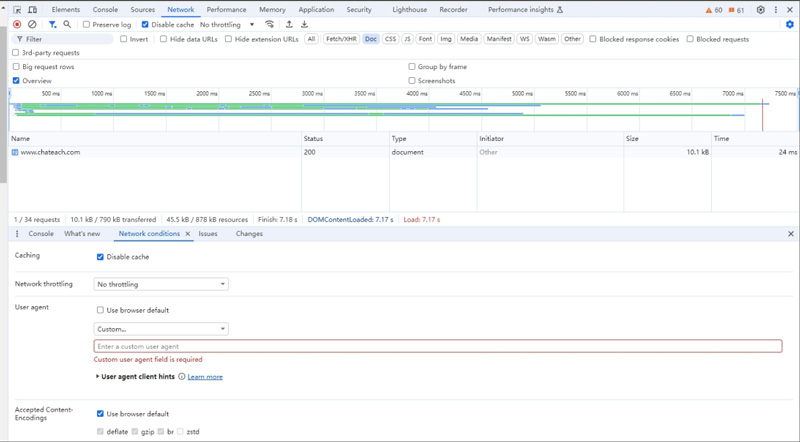
要确认是否属于这种情况也非常的简单,不管站点是通过前端还是后端来处理,只要修改下浏览器的Network conditions选项卡中的user-agent信息为对应的蜘蛛名称,就可以访问到爬虫页,具体的操作访问请关注潘某人SEO后续分享。
对于SEO的影响
搜索引擎的目的是为用户提供准确、有用的搜索结果。如果爬虫页和显示页面存在显著的不一致,且这种不一致是故意为之,那么搜索引擎可能会认为这是一种不诚信的作弊行为。会存在站点被惩罚降权的风险,包括降低搜索排名、减少页面索引量,甚至从搜索结果中完全移除该网站。
如果只是在合理范围的爬虫页和显示页面,且并未对用户体验产生显著影响,搜索引擎可能会给予一定的宽容度。如适配一些搜索引擎的结构化数据。潘某人SEO认为,如果用户显示页面和爬虫页面的内容差异不大,用户体现未受影响,还是数据可行的;但是,非必要还是要尽可能的避免这种粗略,最终结果谁又说的准呢,有实践过的小伙伴可以在评论区分享下。
当用户页面和爬虫页差异较大的情况下,即使没有受到搜索引擎的惩罚,但是这种差异化导致搜索引擎检索页面和实际内容差异较大,不符合用户的搜索预期,这种糟糕用户体验也会导致极高的跳出率,对于转化率和SEO优化都是存在负面的影响。
所以,现在知道为什么搜索结果和实际显示内容不一样的原因了吧,下次遭遇到可以分析其原因而不是充满疑惑了。