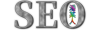
百度爬虫的工作原理
百度爬虫的工作原理是基于抓取环进行的,如下图所示的即为抓取环。抓取器会与网站进行交互,抓取网站的内容,抓取器只要是通过我们常说的百度蜘蛛进行内容的抓取。
抓取到内容之后,搜索引擎会通过特定的算法对页面内容进行分析决定是否进入索引库,同时会进行提链,将这些后链(后链是被抓取页面上存在的链接)加入待抓取池中。然后根据算法,对待抓取URL给到抓取器进行抓取。至此就形成了一个抓取环,只要页面链接设计的合理,在抓取环的作用下可以完成对整个站点完成抓取。

图片来源于百度资源平台
如何保证爬虫正常抓取
URL规范
首先URL需要保证规范性,合理的层数以及长度是非常的重要的。URL的长度需要控制在256个字符内,百度爬虫无法抓取超多256字符的链接,最佳长度是控制在100字符以内。并且URL的层级需要控制在3-5层内,并且url可以清晰表达出页面结构。需要注意的是URL要避免出现中文和特殊字符,搜索引擎无法在链接内容直接识别中文字符,容易出现乱码和抓取问题。
合理发现链路
发现链路可以理解成搜索引擎发现链接的途径,网站的设计需要有合理的栏目设计。搜索引擎通过抓取首页,抓取到网站各个栏目,然后通过各个栏目抓取到整个站点的内容。自上而下的可以高效的抓取到全站的内容。
很多站点的首页设计存在很大的问题,尤其在移动端中尤为明显,采用推荐流的方式,牺牲了站点各个栏目的展现机会,对于用户来说只能获得首页的推荐内容,无法通过对应的栏目入口找到更多的信息,对于搜索引擎也是如此,导致抓取的资源很有限。
如果坚持要使用这种主要方式,那么必须去采用链接提交的方式来弥补不足,但是还是建议采用友好型的聚合首页。需要注意的是链接提交工具,千万不要滥用,去大量提交低质量的内容,会出现被惩罚性打击。
访问友好性
这点主要是从服务器的稳定性来出发的,需要保证页面的加载速度控制在2秒以内。因此建议采用国内知名厂商的服务器,来获取稳定的服务。
同时不要去屏蔽蜘蛛的抓取,页面屏蔽建议通过robots屏蔽。同时需要注意服务器防火墙是否存在对于搜索引擎屏蔽行为。
另外站点需要避免集中提交内容,以免蜘蛛集中大量抓取页面,导致服务器出现动荡。因此站长们需要根据自身的实际情况进行分批提交。