robots文件使用来申明网站哪些内容允许搜索引擎抓取,哪些内容禁止搜索引抓取的;正确的设置robots可以提升搜索引擎对网站的抓取效率,同时避免不必要的内容被抓取展现。但在实际运用中很多站点没有正确的使用robots导致了一些问题,今天潘某人SEO就为大家揭秘下robots的注意点。
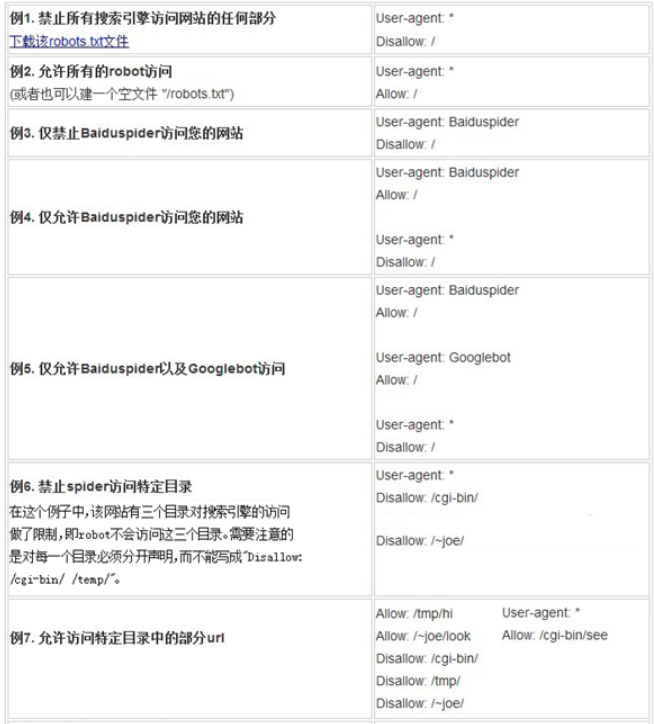
robots如何写
首先我们需要在网站的根目录下创建文件“robots.txt”,文件的编码格式必须为UTF-8;robots文件的访问路径为“域名/robots.txt”,站点需要保证此路径下访问可达性。路径和文件名必须按照上述方式来,不支持自定义。
参数1—User-agent
该项的值用于描述搜索引擎robots的名字,用于指定规则作用的搜索引擎,也是说我们可以通过User-agent指定不同的搜索引擎去执行不同的规则。
# 代表所有的搜索引擎
User-agent:*
# 此处添加所有搜索引擎遵循的规则
# 代表百度搜索引擎遵循的规则
User-agent:Baiduspider
# 百度搜索引擎遵循的规则
2
3
4
5
6
7
如果修改对应搜索引擎的蜘蛛名即可,蜘蛛名可以去各个搜索引擎的官方文档中获取;如果robots规则前后产生冲突的时候,那么就会按照最后的一条规则时执行。如果站点不存在robots文件,那么就是整个网站所有的内容都可以被抓取。
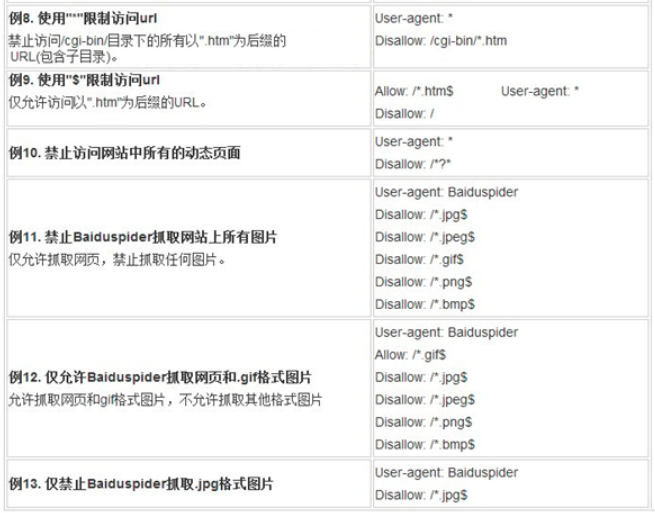
参数2—Disallow
Disallow 是用来定义禁止抓取内容的路径的参数,可以精确到某一条链接,也可以是一个目录。
参数3—Allow
Allow 是用来定义允许抓取内容的路径的参数,可以精确到某一条链接,也可以是一个目录,如果链接或者是目录没有被禁止无需添加也可实现抓取。Allow 的意义更多的在于是,当需要抓取的内容是在被屏蔽的目录之中的,就可以通过Allow 参数来定义被屏蔽的目录下,哪些内容又是可以被抓取的。
robots提交
如果搜索引擎支持robots更新提交一定记得去站长后台提交,因为搜索引擎不会频繁的抓取站点的robots文件,这就会导致规则更新了,搜索引还是会抓取一些不期望被抓取的内容,对站点的seo优化造成影响。
搜索引擎更新robots的周期一般需要1-2周的时间,这也是大家疑惑为什么规则明明正确的屏蔽了,还是被抓取了。此处还是一个非常关键的一点,robots主要是争对未被抓取的内容,如果内容已经被抓取收录,那么再去屏蔽相关路径也是无法删除这些内容的索引。
这种情况就需要大家先robots中做好屏蔽,然后对内容做404状态码返回,然后提交死链来实现索引内容的删除。如果这些内容还是允许被用户访问,但是就不希望被收录就会处理比较复杂。所以说robots一定要创建的早,并且前期做好规划避免后期修改,并在第一时间提交到搜索引擎站长后台,校验并更新robots,然后才是后续站点内容的更新,避免因为robots文件的生效周期问题,导致抓取非允许的内容。