搜索引擎的蜘蛛黑洞指的是搜索引擎蜘蛛在抓取站点内容的时候出现了大量雷同内容的url,导致搜索引擎蜘蛛一直被困在无限的循环中,如黑洞一般。直接的结果就会导致消耗大量的抓取资源。
对于站点来说,每天的抓取额度是有限的,尤其是对于抓取量偏低的站点,则应该更要重视蜘蛛黑洞的出现,要实现高质量内容的优先抓取。长期的蜘蛛黑洞对于站点的收录是非常不利的,轻则影响站点的收录,重则会导致搜索引擎引擎因为有价值内容抓取不到而调低抓取频次。
常见的蜘蛛黑洞
蜘蛛黑洞的主要特征,页面内容相似,或者蜘蛛抓取页面链接会继续进入相类似页面。通常出现在页面的搜索或者筛选页面。
搜索页面当搜索词相近的时候页面的内容是高度重复,而对于站点是无法控制用户不去搜索相似关键词。另外很多站点会有筛选的功能,比如列表页存在通过筛选条件去对页面内容进行筛选,这种情况是最糟糕的,页面内容是在相同的内容中取出不过相同结果的内容,并且url是相同的只是参数不一样。
# 举例有一个列表页面的链接是,内容是seo相关的
https://www.chateach.com/seo
# 当用户筛选,seo相关的算法
https://www.chateach.com/seo?type=seo算法
2
3
4
如上所示的,不管是搜索页面还是页面的筛选,对于相同的页面进行结果的筛选的时候本质上是同一个地址,只是后面的参数不同 ,而对于搜索引擎url带有不同的参数也是作为不同的url内容来抓去对待的。如果当这类页面足够多,搜索引擎便会抓取大量此类页面,抓取获得的内容基本都是相似的。
如何避免蜘蛛黑洞
解决蜘蛛黑洞问题很简单,只需要在robots.txt文件中配置,禁止抓取带有参数的页面就可以实现了,但在实际中部分的带有参数页面也是存在一定价值的,但是这个就需要人工去筛选处理下。
# 屏蔽所有搜索引擎对于动态页面的抓取
User-agent: *
Disallow: /*?*
2
3
对于排除对于这部分动态参数页面的屏蔽,但我更推荐还是屏蔽所有动态参数页面,将有价值的页面人工筛选之后生成独立的页面,如果可以将有价值的搜索结果页面作为tag页面去实现,这个可以根据自己站点情况灵活处理。
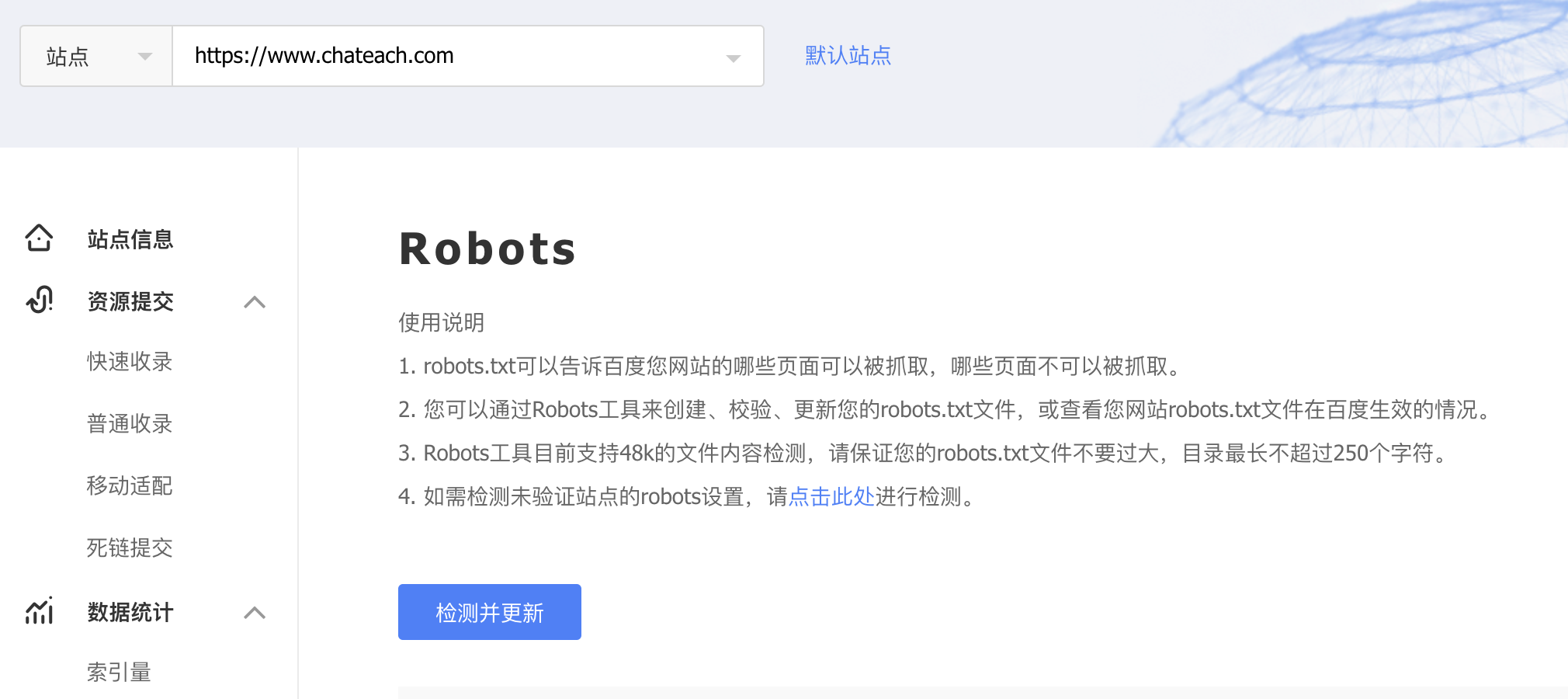
配置好robots文件之后,一般需要等待1周左右的时间生效,对于百度搜索引擎,可以进入站长搜索资源平台刚更新robots加速规则的生效。